




|
|
|
|



|
|
为解决全国或某地区的燃煤机组单位发电量平均碳足迹量化中面临的代表性机组选取难题,给全国煤电碳足迹平均因子量化提供科学支撑,研究聚焦煤电碳足迹非随机样本对总体的代表性分析方法很有必要。煤电作为中国电力行业碳排放主导来源(占比约88%),因装机规模大、影响因素复杂,通过代表性样本分析总体特征成为可行路径。首先,明确煤电碳足迹核心环节为煤炭燃烧(占93.0%)与煤炭获取(占6.5%),合计贡献超99%碳排放,煤耗水平与电煤碳排放因子是影响碳足迹的本质因素;然后,提出基于已有百余个量化样本构建代表性新样本的3类方法,包括通过关键参数一致性验证间接证明代表性、按多维度分层补充缺失样本、加权重抽样匹配总体分布等;最后,基于现有数据组合生成171个样本数据集,其发电煤耗(286.9 g/(kW·h))、单位热值含碳量(26.39 t/TJ)与1964个电厂组成的总体对应指标(286.7 g/(kW·h)、26.28 t/TJ)偏差仅为–0.07%、–0.415%,验证了所提方法的有效性。
(来源:《中国电力》 作者:王志轩, 张晶杰, 石丽娜, 等)
研究背景
电力行业碳排放是全球最大的二氧化碳排放源,也是中国实现“双碳”目标的关键领域,电力行业的碳排放约占中国二氧化碳排放总量的40%,其中煤电占比高达89%,是中国碳排放控制的重点。因此,准确量化全国煤电行业碳排放对构建电力行业碳排放统计体系、制定科学降碳路径具有重要意义。全国单位千瓦时上网电量的平均碳足迹(以下简称煤电碳足迹)是一项完整、科学的量化指标,确定这一指标的关键在于从中国类型多样、分布广泛的燃煤机组中,筛选出具备代表性的样本。
中国燃煤发电装机容量已约达12亿kW,占全球煤电装机容量的50%以上,且存在机组容量等级、技术水平、功能(纯凝汽式发电与热电联产发电)、地域分布、电煤品种、电煤运输方式等差异情况,涉及碳足迹量化全生命周期各环节的影响因素各不相同。若对所有燃煤电厂逐一开展碳足迹量化,以获得全国平均煤电碳足迹因子,不仅没有必要,而且从人力、物力、财力角度而言也难以实现。
当前,煤电碳足迹量化研究主要集中在2个层面:一是基于生命周期评价(life cycle assessment,LCA)的单机组或典型企业碳足迹测算,侧重于方法学探讨与个案分析;二是基于行业统计数据的宏观排放因子估算,如国际能源署(International Energy Agency,IEA)、国家统计局等发布的排放因子数据库。然而,现有研究仍存在明显不足:一方面,针对全国尺度煤电碳足迹的系统性量化方法尚未成熟,尤其是如何在样本非随机、数据不完备的情况下构建代表性样本;另一方面,多数研究依赖随机抽样或典型抽样,但受限于企业配合度、数据可及性等因素,在实际操作中难以实现,且缺乏对非随机样本代表性验证的系统方法。因此,探索适用于中国煤电行业特定的非随机样本代表性分析方法,成为提升全国碳足迹量化科学性与实操性的关键问题。
本文聚焦于从已完成碳足迹量化的样本中,通过非随机抽样的方法构建具有代表性新样本的数理方法,旨在解决随机抽样在煤电碳足迹量化中难以实施的难题。一是提出关键参数一致性验证的框架,通过煤耗、电煤含碳量等核心参数的分布一致性,推断样本碳足迹的代表性;二是构建分层抽样扩充与加权重抽样相结合的方法体系,在样本覆盖不全或分布偏差时,通过补充样本或调整权重实现对总体特征的重构;三是形成一套可操作的样本构建与验证流程,结合中国煤电行业实际数据,验证方法在减少样本量、提升代表效率方面的有效性。
影响煤电碳足迹量化的主要环节及因素
1.1 煤电碳足迹量化方法依据及量化边界
煤电碳足迹量化结果最关键的影响因素是量化方法,采用不同方法得出的碳足迹结果不具备可比性。中国生态环境部提出并指导制定的GB/T 24067—2024《温室气体 产品碳足迹 量化要求和指南》已于2024年10月1日正式实施。该标准修改采用国际标准化组织(ISO)发布的ISO 14067标准,与中国GB/T 24040、GB/T 24044环境管理生命周期评价方法相一致。依据GB/T 24067—2024,中国电力企业联合会制定了团体标准T/CEC 1048—2024《温室气体 产品碳足迹量化方法与要求 燃煤发电》,为中国单个煤电企业电能产品碳足迹量化、全国电能产品碳足迹量化,以及中国碳足迹数据的国际交流互信奠定了基础。
与核算产品生产过程中的碳“直接排放”因子相比,产品碳足迹因子的显著差异在于产品生产过程的碳排放涵盖了从“出生”到“死亡”生命周期各阶段的“直接排放+间接排放–移除量”,即生命周期阶段的净排放量。不同碳排放管理要求、不同产品在不同阶段的碳排放差异大,由此形成了不同的碳足迹量化范围要求。根据GB/T 24067—2024的要求,结合国内外普遍做法,燃煤电厂碳足迹量化需要覆盖5个环节:原料开采与生产(煤炭、柴油等)、材料开采与生产(石灰石、尿素、催化剂等)、能源生产(电力)、运输(原料、材料、废物)、废物利用与处置(粉煤灰、炉渣、石膏、危废)。典型燃煤发电碳足迹量化的边界如图1所示。
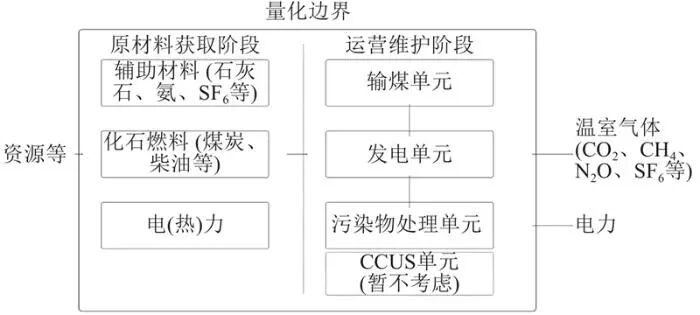
图1 典型燃煤发电碳足迹量化边界示意
Fig.1 Quantification boundary of carbon footprint for typical coal-fired power generation
典型的煤电生产阶段可划分为输煤单元、发电单元和污染物处理单元。其中,输煤单元包括煤炭采购运输、配煤、煤炭采制化等;发电单元包括锅炉、汽机等汽水系统,发电机、变压器等电气系统,以及控制系统等;污染物处理单元包括脱硝、除尘、脱硫系统及灰库、灰场等。若燃煤电厂配备碳捕集利用与封存(carbon capture,utilization and storage,CCUS)单元,则需要根据其工艺流程在不同阶段予以考虑。各生产单元的碳足迹量化还需要涵盖设备生产、电厂建设及寿命终止后的处置回收环节。
IEA对电力生产生命周期排放因子的量化边界包括:发电所需燃料或原材料的开采和生产、发电过程排放、各原材料运输至发电厂的排放、发电设施的建造安装,以及与电厂运营维护、燃料及设施处置/退役相关的持续排放。中国燃煤电厂碳足迹量化边界与IEA在原则上是一致的。
1.2 生命周期不同阶段煤电碳足迹的权重及燃烧环节要点分析
根据国家能源集团、大唐集团和中煤集团测算结果,煤炭燃烧阶段的碳排放占煤电产品碳足迹的93.0%,煤炭获取阶段占6.5%,材料和设备获取过程、电厂建设及退役阶段等其他环节的排放量占比不足0.5%。可以说,对于煤电碳足迹只要量化到燃烧排放和燃料获取环节的排放,则可以视同煤电产品的全生命周期排放。煤电产品碳足迹各阶段排放占比如图2所示。
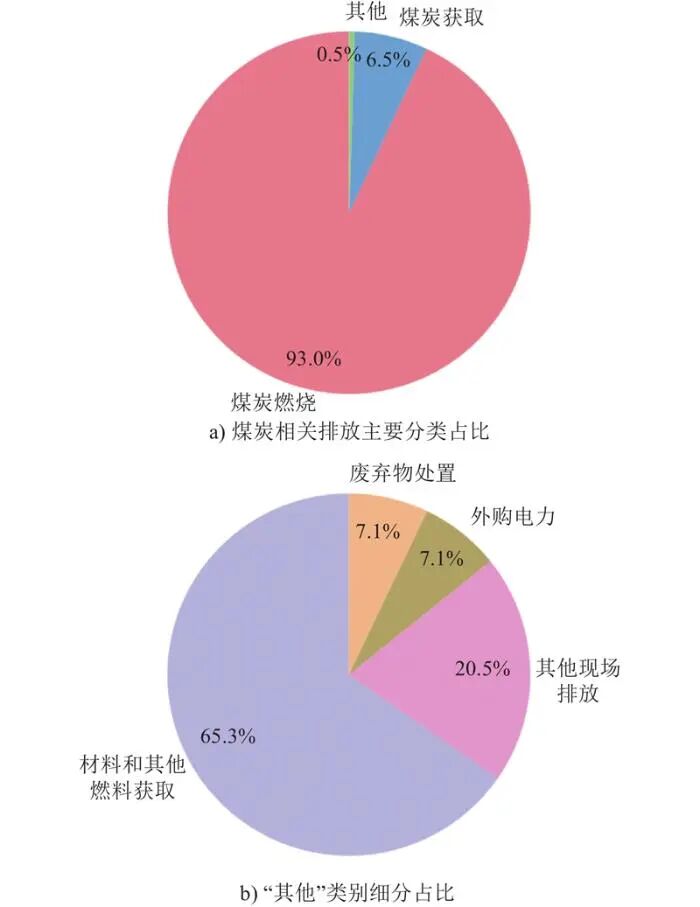
图2 碳足迹试算机组在生命周期阶段各类别排放占比(含基建设备)
Fig.2 Proportion of various categories of emissions in the life cycle stage of the power units (including the infrastructure equipment) for carbon footprint calculation
纳入碳足迹量化的温室气体包括二氧化碳、甲烷、氧化亚氮等。在燃烧环节,燃煤电厂碳排放主要源于燃料中元素碳氧化生成的二氧化碳。尽管煤中的氮元素或空气中的氮气在燃烧过程中也会形成氧化亚氮,但其在常规燃煤机组温室气体排放中的占比很低,以二氧化碳当量计算通常小于1%。因此,对煤电燃烧环节碳排放起绝对主导作用的温室气体是二氧化碳。
煤电机组单位发电量二氧化碳排放量也可称为煤电二氧化碳排放因子,其基础计算公式为
式中:Cf为燃煤发电由于煤炭燃烧排放的二氧化碳因子,kg/(kW·h);f为发电过程煤炭消耗量,t;q为煤炭平均低位发热值,kJ/kg;c为单位热值含碳量,t/TJ;o为煤的碳氧化率,%;w为发电量,kW·h。
式(1)本质上是基于物质守恒定律和燃料燃烧的基本化学反应,且被国际公认的碳量化指南广泛采用。
为统一计算元素,发电过程煤炭消耗量f可转换为能量消耗量,以“标准煤”表示为
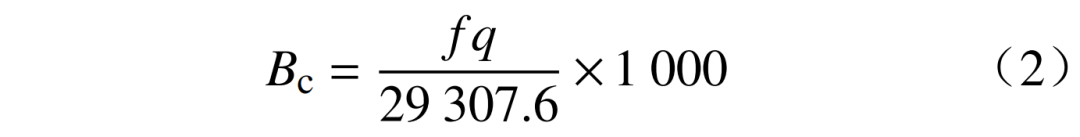
式中:Bc为发电过程标准煤耗量,kg;1 kg标准煤热量为29307.6 kJ/kg。
将式(2)转化代入式(1)可得
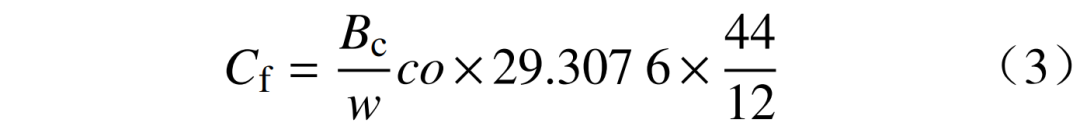
式(3)简化可得
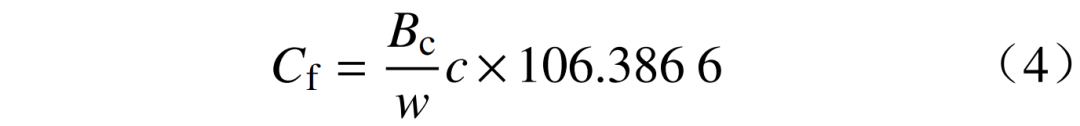
因此,只需要判断单位发电量的能量消耗量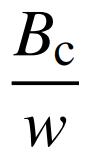 和单位能量(热值)含碳量c对于结果的影响,即可有针对性地完成样本的选择工作。本文以由现场实测的373组数据作为基准范围,利用Sobol方差分解法对燃煤机组单位发电量二氧化碳排放量进行敏感性因素分析,结果如图3所示。由图3可知,发电过程的单位千瓦时标准煤耗量
和单位能量(热值)含碳量c对于结果的影响,即可有针对性地完成样本的选择工作。本文以由现场实测的373组数据作为基准范围,利用Sobol方差分解法对燃煤机组单位发电量二氧化碳排放量进行敏感性因素分析,结果如图3所示。由图3可知,发电过程的单位千瓦时标准煤耗量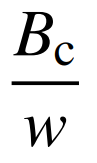 对最终结果起主导作用,其对单位发电量碳排放的方差贡献率为96.2%。
对最终结果起主导作用,其对单位发电量碳排放的方差贡献率为96.2%。
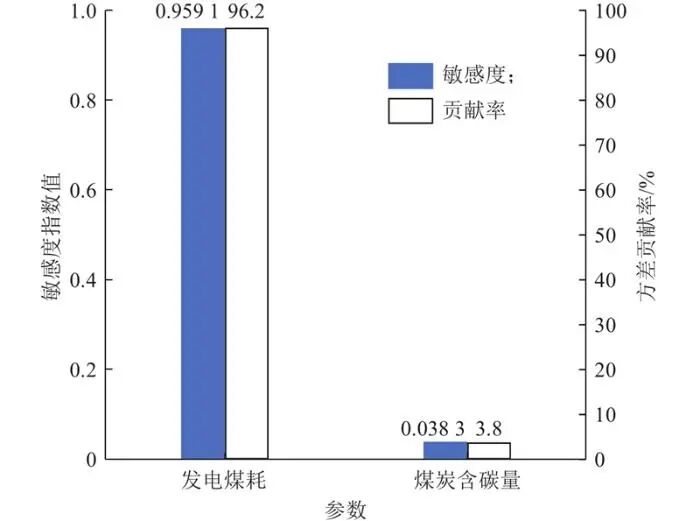
图3 方差贡献率分析
Fig.3 Analysis of variance contribution rate
1.3 煤炭获取环节碳排放的要点成分
煤炭获取阶段的碳排放是影响煤电碳足迹因子的第二大因素,该环节碳排放主要分为坑口电站和非坑口电站两大类型。坑口电站的煤炭与电厂之间呈稳定供应关系,且运输环节的碳排放量较低;非坑口电站的煤炭供应往往呈现多元供应形态。具体计算公式为:坑口电站煤炭获取排放是煤炭生产过程排放因子与入厂煤量的积;非坑口电站煤炭获取排放则需要考虑煤炭生产过程排放量与煤炭运输环节排放量。
在煤炭获取环节,煤炭生产过程的排放量占主导地位,且该过程碳排放的主要成分是甲烷。煤炭开发利用过程中的碳排放量占比约10%,甲烷排放量占能源活动甲烷总排放量的80%以上,约占中国甲烷总排放量的1/3。在煤电碳足迹量化过程中,煤炭获取环节的碳排放数据较难获得,但可通过综合分析国家温室气体排放清单相关数据、各类数据库资料及文献资料,将其应用于具体样本的量化。本研究基于国家能源集团和中煤集团的现场实测活动数据,结合Ecoinvent 3.10中给出的中国煤炭开采过程甲烷排放因子,计算得到了更切合实际的煤炭开采过程的甲烷排放量,使全国煤电碳足迹因子中煤炭获取阶段的碳排放贡献处于合理范围。
综上分析可知,对单一煤电企业(机组)碳足迹量化结果影响最大的要素是单位发电量的煤耗水平(即煤电效率),其次是电煤的单位热值含碳量。进而,对于全国煤电碳排放因子的量化而言,只要碳足迹量化样本中煤耗分布、电煤单位热值碳含量分布与总体分布具有统计学上代表性,则通过样本特征的分析,可以得出全国煤电碳足迹因子的特征。
煤电机组的容量及参数、是否为热电联产机组、所在地区、运行小时数等因素,均会对煤电碳足迹量化结果产生影响。但从本质来看,这些因素的影响最终都会体现在发电煤耗及煤炭本身的质量(元素碳、发热量等要素)上。只要抓住核心影响因素,就能采用科学方法分析样本对整体的代表性。
非随机样本选取方法
2.1 基本考虑
从工作组织与协调看,碳足迹量化涉及多方面因素:专业队伍的能力水平、被量化电厂的配合程度(上级单位是否同意,是否积极主动,是否愿意提供真实数据等)、碳足迹量化直接数据的获取与真实性、相关产业链及供应链实时数据与历史数据的可获得性及真实性(如煤矿相关数据)、服役期满后设备处置的分析评估,以及电厂关联电网(调度)部门的配合等。显然,依据概率论经典方法开展抽样,并以此进行碳足迹量化与分析,在实际操作中存在较大难度(例如抽到的企业样本不具备碳足迹量化条件等)。
为实现以样本代表总体的目标,实际工作中可采取2种路径:一是选择某一具有全国煤电碳足迹代表性的能源(电力)集团公司,在其管理范围内选择代表性发电企业组成量化样本,通过样本数理分析得出全国煤电碳足迹总体特征;二是对已有的量化成果,通过数理分析组合成能够代表总体特征的新样本,再通过数理分析得出总体特征。
本文主要采用第2种路径,核心目标是让新样本准确反映煤电行业碳足迹的整体分布规律,为量化全国煤电的碳足迹因子及全国电力行业碳足迹评估提供可靠基础。
2.2 构建适合总体特征的非随机样本
首先要有明确的总体关键统计参数支撑,即已知总体的核心指标统计数据,包括平均发电煤耗、平均单位热值含碳量,及其标准差、中位数等。其次要有足量的量化样本,且样本已获取核心特征参数及量化结果。最后研究的目标聚焦“总体整体表征”,无需拆分技术、燃料、地域等细分维度,仅需要通过样本推导总体的整体分布规律。
全国共有2000个电厂,若已知其平均发电煤耗、平均单位热值含碳量及其标准差、中位数等相关统计参数,现须量化所有电厂的单位电量碳排放量。结合敏感性分析,碳排放与煤耗及煤炭单位热值含碳量存在强关联关系,但其具体关联性暂无准确数据,因此选择数百个电厂作为样本来计算单位电量碳排放量。需要说明的是,样本电厂并非随机选取,而是按一定条件选取,且已获取全部样本的发电煤耗与燃煤单位热值含碳量等特征参数。
要证明非随机选取的样本电厂其碳排放特征参数能代表全国2000个电厂总体特征,核心逻辑是:利用“碳排放与煤耗及煤炭单位热值含碳量强关联”,通过统计分析验证样本与总体在煤耗及煤炭单位热值含碳量的统计分布上的一致性,间接证明碳排放特征的代表性。
具体做法通过以下步骤实现。
1)确定关键统计量及可接受阈值。
对样本和总体的关键统计量进行对比时,需要先明确判断依据及可接受阈值(主要通过经验判断或专家调查确定)。例如,选取的关键统计量及样本与总体分布偏差(见式(5))的可接受阈值为:均值<5%、标准差<10%、中位数<5%、偏度<0.2、峰度<0.5。
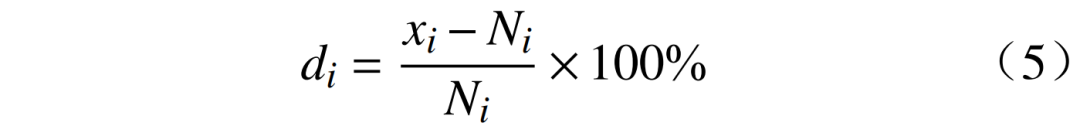
式中:di为样本关键统计量与总体差异率;xi为样本关键统计量,包括均值、标准差、中位数、偏度、峰度等;Ni为样本关键统计量,包括均值、标准差、中位数、偏度、峰度等。
2)主要指标分布形态的可视化与检验。
首先估计总体2个参数的分布形态及关键统计指标。绘制样本与总体的煤耗及燃煤单位热值含碳量的直方图、核密度曲线(kernel density curve),直观观察二者分布形状(如是否均为正态分布、偏态方向是否一致)。基于现有样本的正态分布假设需要通过 Shapiro-Wilk 检验验证,若不服从正态分布,可采用核密度估计法(通过核函数平滑化原始数据,生成连续的密度曲线)生成新样本。
然后根据以上工作成果,选择使用Kolmogorov-Smirnov 检验(K-S 检验) 或Anderson-Darling 检验,检验样本煤耗分布是否与总体煤耗分布一致(原假设:样本与总体分布相同)。若检验结果不显著(p>0.05),可认为分布形态一致。
最后进行分位数一致性检验。比较样本与总体在关键分位数(如25%、50%、75%、90%分位数)的煤耗值,计算差异率di。若各分位数差异率均在可接受阈值内,说明样本在煤耗的“高低端分布”上与总体一致(例如:高煤耗电厂、低煤耗电厂的比例和水平一致)。
2.3 分层抽样扩充法
分层抽样扩充法更适用于“子层样本缺失但相邻层特征可参考”的场景(如某容量机组样本为0,但同类技术机组数据可借鉴)。使用以下方法深入反映不同维度的碳足迹差异。
步骤1:明确研究样本。
1)确定煤电碳足迹的总体特征维度。
煤电“总体”碳足迹因子,是指基于国家统计局口径(或电力行业统计口径)内的煤电装机容量所对应的发电量的碳足迹,其功能单位为每千瓦时煤电碳排放量。要深入反映不同维度的碳足迹差异,可从不同维度进行拆分。技术特征:机组类型(亚临界、超临界、超超临界、循环流化床等)、机组容量(300 MW、600 MW、1000 MW等)、机组性质(纯凝机组、热电联产机组);燃料特征:煤炭类型(动力煤、褐煤、无烟煤等)、煤炭热值、含碳量;地域特征:煤炭产地与电厂距离(影响运输碳排放)、区域电网结构(影响厂用电碳排放);生命周期阶段特征:上游(煤炭开采)、中游(运输)、下游(发电+废弃物处理)各环节的碳排放占比。
将以上维度在总体中的分布比例作为新样本的“目标分布”。
2)基于现有样本构建符合总体特征的新样本。
根据现有样本的规模、分布偏差类型(如某类机组样本过多/缺失),可选择分层抽样扩充法、加权重抽样法2种方法构成新样本。
按上述特征维度将总体划分为若干子层(如“华北地区+ 600 MW超临界机组+动力煤”为一个子层),计算每个子层在总体中的占比(如 5%)。
步骤2:评估现有样本的分层覆盖度。
统计现有样本在各子层的数量,若某子层样本量为0或远低于“目标占比×总样本量”(如目标5%×1000=50个,但现有仅10个),则需要补充该层样本。
步骤3:生成缺失层的新样本。
对样本不足的子层,基于该层现有样本的碳足迹特征(如单位发电量碳排放均值、各环节占比),通过“参数模拟”生成新样本。例如:已知某子层现有10个样本的发电环节碳排放服从均值800 g/(kW·h)、标准差50 g/(kW·h)的正态分布,则可基于该分布随机生成40个新样本,补充至50个。
若子层完全无样本,可参考相邻相似层(如“华北地区+600 MW 超临界机组+褐煤”)的特征,调整燃料相关参数(如褐煤含碳量更高,碳排放均值上调15%左右——根据烟煤与褐煤的碳排放因子的差异)后生成样本。
2.4 加权重抽样法
若所有关键子层均有样本,但部分子层的样本占比与总体占比差异显著,可以采用加权重抽样法对样本分布的偏差进行修正。
步骤1:计算样本权重。
对现有样本,按其所属子层在总体中的占比(记为 P)与在现有样本中的占比(记为 p)的比值赋予权重:权重= P/p。例如:某子层在总体中占10%(P=0.1),但在现有样本中仅占5%(p=0.05),则该层所有样本的权重=0.1/0.05=2(即该层样本的代表性翻倍)。
步骤 2:基于权重重抽样。
采用 Bootstrap 重抽样法(此方法是放回抽样,保留样本分布特征的方法),按样本权重概率抽取样本(权重越高,被选中概率越大),生成与目标总样本量一致的新样本集。当子层样本量至少有30个时,重抽样结果稳定性更高;若样本量低于10个,则需要结合专家判断调整权重系数。
此方法无须生成全新样本,仅通过调整抽样概率即可让新样本分布贴近总体;但若某子层现有样本量极少(如低于5个),权重会过大,可能导致新样本重复度过高,需要结合分层抽样扩充法或加权重抽样法补充基础样本。
步骤3:验证,确保新样本符合总体特征。
新样本构建后,需要通过统计检验验证其与总体的一致性。
1)分布检验:用 K-S 检验(连续变量,如碳排放值)、卡方检验(分类变量,如机组类型)验证新样本与总体的分布是否无显著差异(p>0.05)。
2)统计量对比:计算新样本的关键统计量(如碳排放均值、各环节占比),与总体已知数据(如行业平均碳排放)的偏差要小于5%。
3)敏感性分析:对核心特征(如机组容量)分组,检查新样本中各组的碳足迹规律是否符合行业认知(如超超临界机组碳排放低于亚临界机组)。
加权重抽样法在子层样本量低于5 个时,权重调整可能导致结果失真,此时需要结合专家判断进行修正。
非随机样本方法在中国煤电碳足迹量化过程中的应用
3.1 与供电煤耗、电煤质量相关的煤电总体数据
1)已有的电力统计权威报告、数据库及专业分析资料。
《中国电力统计年鉴》《中国电力统计分析报告》《中国电力发展年度报告》《全国电力可靠性年度报告2024》等公开报告,以及国际能源署(IEA)发布的相关报告,均以宏观统计为主;《电力工业统计资料汇编》等相关数据库虽然可以查询历年全国电煤消费情况、煤电发电量、供电标准煤耗、人均用电量等统计数据,但均为单一统计值,数据颗粒度较低,无法呈现具体数值或多数值共同作用后的分布情况,难以满足本研究分析要求。
2)煤电结构情况。
根据中国电力企业联合会发布的报告,截至2024年底,全国全口径发电装机容量达33.5亿kW,分类型看,水电4.36亿kW,火电14.4亿kW(煤电11.9亿kW,气电1.4亿kW,生物质发电4597万kW),核电6083万kW,并网风电5.2亿kW(其中陆上风电4.8亿kW,海上风电4127万kW),并网太阳能发电88742万kW(其中,光伏发电88654万kW,含集中式光伏51099万kW,分布式光伏37555万kW)。
2024年纳入中电联可靠性统计的火电机组中,燃煤机组共1952台,总装机容量9.17亿kW。其中,1000 MW及以上容量机组175台,总容量1.77亿kW,占统计燃煤机组装机容量的19.33%;600~699 MW容量机组614台,总容量3.89亿kW,占比42.38%;300~399 MW容量机组913台,总容量2.97亿kW,占比32.40%;200~299 MW容量机组114台,总容量0.23亿kW,占比2.55%;100~199 MW容量机组114台,总容量0.16亿kW,占比1.74%;其余容量等级机组22台,总容量0.15亿kW,占比1.60%。
3)煤电机组的煤耗及碳排放相关要素特征。
中国电力企业联合会的环保低碳专项统计数据,覆盖包括五大电力集团(央企)在内的数十家发电集团、上百家发电企业及近2000家燃煤电厂(机组),涵盖全国70%以上容量的燃煤机组,具备广泛的行业代表性。
该统计体系涵盖装机容量、发电量、燃料消耗量及负荷等基础生产数据,燃料元素分析等原料特性数据,脱硝、除尘、脱硫等环保设备信息,以及主要污染物排放、碳排放等核心环保低碳指标,数据来源规范、覆盖范围全面、指标体系完整,形成了全链条、多维度的数据体系。
本文对2024年燃煤机组环境统计数据进行分析后,得到供电煤耗、燃煤含碳量等数据的分布特征如图4所示。
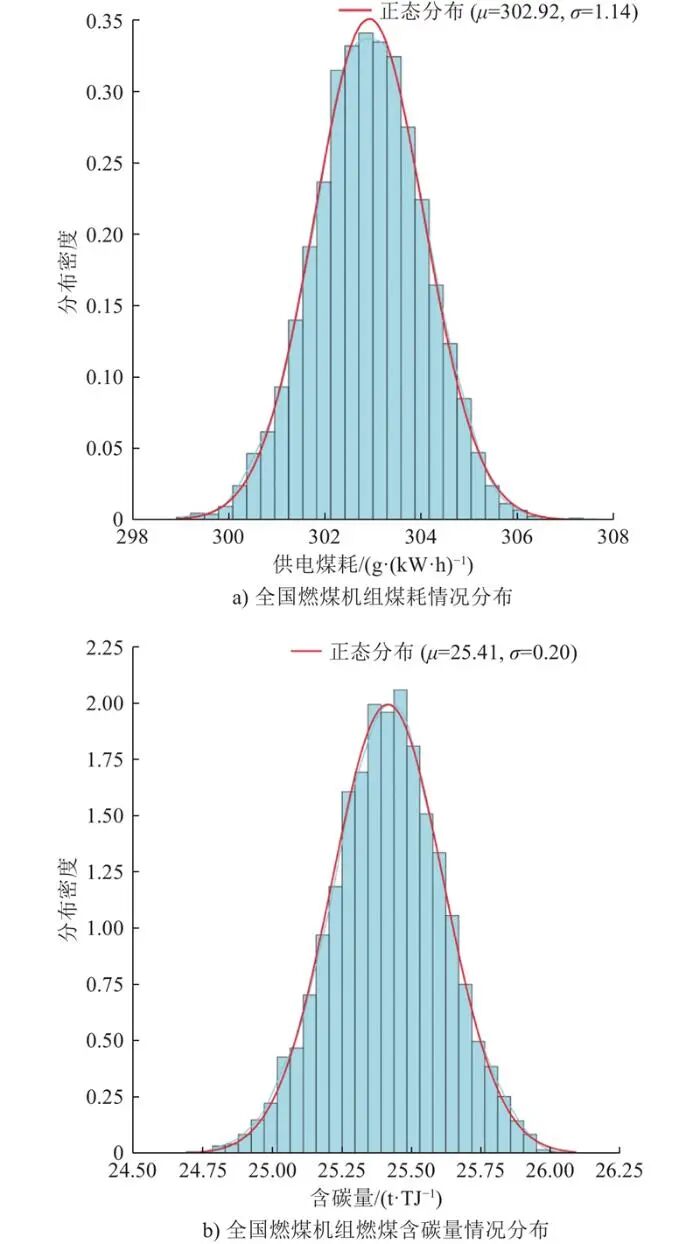
图4 根据燃煤机组环境统计数据测算得到的分布特征
Fig.4 Distribution characteristics obtained through calculation based on environmental statistical data of coal-fired units
全国燃煤机组煤耗为302.89±2.20 g/(kW·h),收到基含碳量为25.41±0.39 t/TJ。根据发电量加权计算的平均发电煤耗为301.35 g/(kW·h);根据燃煤量加权计算的燃煤平均收到基含碳量为26.28 t/TJ。
3.2 方法的选取及应用
根据目前掌握的总体数据情况,本文选择直接构建适合总体特征的非随机样本。本质是现有数据条件与研究目标高度匹配,具备总体统计数据支撑,已知全国1964个电厂的关键统计参数,可通过“煤耗+单位热值含碳量”的分布一致性,间接验证碳排放特征的代表性,满足方法的核心数据需求。在已有样本的规模与质量方面,也符合方法的要求,本文基于国家能源集团、中煤集团共393台燃煤机组,严格按照团体标准T/CEC 1048—2024量化得到了各样本机组的发电碳足迹因子,样本覆盖全国26个省(市、自治区),样本机组燃用煤炭来源于中国主要煤炭产区和主要海外进口国,具有较好的地理代表性,入炉煤量、燃烧排放量、外购电量以及大宗耗材使用量等活动数据均来自2024年碳核算数据和台账数据,具有良好的时间代表性,且所有样本均可获取“发电煤耗+燃煤单位热值含碳量”等核心参数,无须额外补充基础样本,具备直接分析的条件。第1种方法的“整体分布验证”逻辑完全适配该目标,且成本最低、效率最高。
对已有量化成果的393个样本进行筛选组合的具体流程如下。首先对初始数据进行清洗,剔除关键参数缺失或明显异常的样本±3σ,确保数据质量可靠。其次,对筛选出的样本数据开展关键维度分层(如机组容量、区域分布),确保整体样本不过度集中。最后,从各层中随机抽取若干机组数据,对抽取机组的典型参数(发电煤耗、电煤含碳量)进行分布统计,与全国总体统计参数的分布及偏差进行对比,若各项偏差均符合本研究设定的阈值,则确定样本,若不符合,则重新抽样,直至样本构成符合要求。本研究通过以上步骤,组合成能够代表总体特征的171个新样本集合,进而得出总体特征。样本集合与总体的核心数据对比情况如表1所示。由表1可知,171个样本与1964个总体样本相比,其发电煤耗、单位热值含碳量的偏差分别为–0.07%和–0.415%。
表1 非随机样本选取与总体特征参数的对比
Table 1 Comparison between non-random sample selection and population characteristic parameters
由于2组数据样本自由度差异较大,采用合并自由度进行显著性检验。得到发电煤耗和单位热值含碳量的样本与总体显著性检验p值均大于0.05,即样本的发电煤耗和单位热值含碳量与总体分布一致。
结论及建议
4.1 结论
本文围绕煤电碳足迹量化中非随机样本代表总体的方法开展研究,核心目标是解决随机抽样在煤电碳足迹量化中面临的实操难题,为科学量化全国煤电碳足迹因子、支撑电力行业碳排放精细化管理提供方法论支撑。本文在煤电碳足迹量化中系统提出了基于关键参数一致性的非随机样本代表性验证,构建了分层加权重构方法体系,实现了在有限样本条件下对总体碳足迹特征的科学推断,为行业碳足迹大数据应用提供了方法论补充。但本方法依赖于总体关键参数的已知性,若总体数据缺失或更新不及时,可能影响样本构建效果。
主要结论如下。
1)明确了煤耗水平和电煤的碳排放因子是煤电碳足迹因子的核心影响要素,确定了以GB/T 24067—2024等标准为依据,覆盖煤炭开采、运输、发电、废弃物处理等阶段生命周期碳足迹量化方法。研究表明,煤炭燃烧(约93.0%)与煤炭获取(约6.5%)2个阶段是煤电发电量碳足迹因子核心贡献环节,机组容量、地域分布等特征均通过核心影响要素间接作用于碳足迹结果。
2)提出了非随机样本代表性验证与构建的系统方法。针对已量化得到的非随机样本,构建了以关键参数一致性检验为核心的验证框架,并结合分层抽样扩充法与加权重抽样法,实现了样本分布与总体特征的对齐。本方法克服了传统随机抽样在数据可及性、企业配合度等方面的局限,为在有限样本下推断总体特征提供了数理依据。
3)基于全国1964个电厂的总体数据与393个量化样本,构建了171个新样本,结果显示,新样本与总体样本在发电煤耗和单位热值含碳量高度一致,且统计检验表明分布无显著差异,验证了本文方法在实证数据中的有效性与适用性。
4.2 建议
1)推动行业数据标准化与共享。加强碳足迹相关数据在电力行业环保统计中的系统性工作,建立全国煤电碳足迹基础数据库,为样本代表性分析提供更全面的总体基准。
2)拓展方法在特殊机组与动态场景中的应用。针对热电联产机组、CCUS技术应用机组等特殊类型,应进一步开发分层策略与权重调节机制,如对热电联产机组,可按“发电/供热比”分层,并按“单位发电碳排放”与“单位供热碳排放”分别量化。应建立样本动态更新与验证机制,应对行业结构变化与技术演进。
3)加强技术工具开发与行业推广。开发煤电碳足迹样本分析工具,集成数据校验、分层抽样模拟、权重计算等功能,提升新样本构建的效率和科学性。同时,选取典型区域或大型能源集团开展试点应用,验证本研究方法在不同场景下的适用性。
4)探索方法在其他高耗能行业的迁移应用。建议将本研究提出的关键参数一致性+分层加权框架推广至钢铁、水泥等行业,为非随机样本在工业碳足迹量化工作中的应用提供参考。




|






- 西安热工研究院有限公司
- 中国电机工程学会
- 国家核电技术公司
- 中国电力科学研究院
- 火力发电分会(电机工程学会)
- 火力发电分会(中电联)
- 中国电力规划设计协会
- 中国电力建设企业协会
- 华润电力控股有限公司
- 国电电力发展股份有限公司
- 华能国际电力股份有限公司
- 大唐国际发电股份有限公司
- 中国华电工程(集团)有限公司
- 山东黄台火力发电厂
- 中国华电集团发电运营有限公司
- 内蒙古蒙电华能热电股份有限公司
- 园通火力发电有限公司
- 广西柳州发电有限责任公司
- 株洲华银火力发电有限公司
- 内蒙古岱海发电有限责任公司
- 山西漳山发电有限责任公司
- 湖北华电黄石发电股份有限公司
- 黑龙江华电佳木斯发电有限公司
- 陕西蒲城发电有限责任公司
- 福建华电永安发电有限公司
- 开封火力发电厂
- 华电国际邹县火力发电厂
- 中山火力发电有限公司
- 山西阳光发电有限责任公司
- 国电长源电力股份有限公司
- 山东新能泰山发电股份有限公司
- 宜昌东阳光火力发电有限公司
- 扬州火力发电有限公司
- 太仓港协鑫发电有限公司
- 甘肃电投张掖发电有限责任公司
- 陕西渭河发电有限公司
- 国投钦州发电有限公司
- 大唐淮南洛河发电厂
- 国电丰城发电有限公司
- 靖远第二发电有限公司
- 国华绥中发电有限公司
- 元宝山发电有限责任公司
- 开封火力发电厂
- 云南华电巡检司发电有限公司
- 云南华电昆明发电有限公司
- 国投宣城发电有限责任公司
- 山东黄岛发电厂
- 国投北部湾发电有限公司
- 西北发电集团
版权所有©火力发电网 运营:北京大成风华信息咨询有限公司 京ICP备13033476号-1 京公网安备 110105012478 本网站未经授权禁止复制转载使用